Also known as “Help! Our Mongo DB is almost full!“
At the start of this year, the Mongo DB used by one of our instances was quickly filling up. We were advised to purge data – but we didn’t have any data we could just delete!
This was not going to be as easy, we were already on an XL instance so vertically scaling to a larger cluster was not an option.
For Horizontal Scaling we could have looked at sharding – Mongo DB team advised it is better to start off with sharding instead of trying to migrate to a sharded architecture. It would also have been expensive – as well as doubling our data nodes, there are additional servers required in a sharded configuration.
The next option was to look at archiving data, but there was no strategic solution for archiving data from Mongo DB.
So I implemented our own archival solution using Object Storage, which is transparent to end users and downstream clients of the application.
We have been running the archival process in Production for the past couple of months, and estimate we have to keep running for at least another month to reach the target 60% disk usage. Archival is running slowly so as to not impact BAU and keep our Mongo OpLog above 24 hours, so far we have archived approx. 2.5 Billion file records from MongoDB, which has freed 500GB of the 2.5TB disk capacity.
Now for some of the detail:
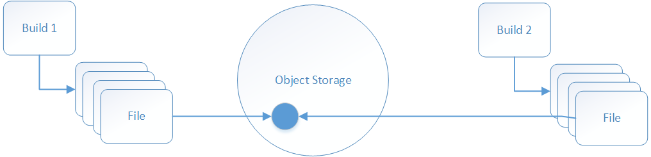
For each build, we record details of each source code file along with a fingerprint and store this in MongoDB, along with details of where the actual files contents are stored in Object Storage. The result of this, if a build has 10k source code files, each time a build runs we will be storing 10k file records in MongoDB. However, it means we only store one copy of each unique file in Object Storage.
As a result, 98% of our data usage is due to the files collection!
The Plan – we will only archive File records which will be grouped by build. So for any build we can retrieve all archived file records.
Data model changes
The file records contain the fingerprint to Object Storage mapping, so if we delete the last file record for any file stored in Object Storage, our service will forget it already has a copy of that file and de-duplication will break.
This was resolved by creating a new collection to specifically store this mapping information. Data migration to populate this collection would take a while, so the application currently uses both old and new method to perform de-duplication.
Archival
Using Node.JS streams, we stream a list of file records from MongoDB, through a number of stages and into Object Storage.

For each file records, we ensure the data migration has taken place, then the records are transformed to NDJSON format, which is New-Line Delimited JSON.
With NDJSON, each record is stored on a single line in valid JSON, however the file as a whole is not a valid JSON file.
With NDJSON we do not need to load and parse the JSON in order to process it, we can easily stream line by line and process each line individually, which helps avoid a large memory overhead. This is useful when a build can have 140k source files.
Once we have archived the file records, we store the Object Storage information on the Build record, once this is saved we can now delete the file records for that build.
Restoration
For restoring archived files back to Mongo:

We can stream the NDJSON file contents from Object Storage, process it line by line, parse the JSON and save to Mongo.
Initially this was slow, taking an hour to restore 34k files, so we added another part to the pipe:

Grouping file records into batches of 250 records and doing a bulk insert brought the restore time down to less than 1 minute – acceptable.
No Restore Needed
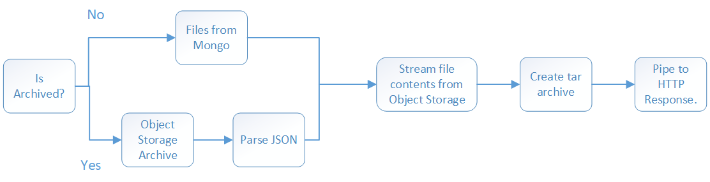
The primary reason to need old file records for a build is for downloading a tar of all source code.
Which looks something like:

I updated this process to allow this to transparently happen for archived builds without needing to first restore the records to Mongo.
Performance of downloading source for an archived build is now comparable to a non archived build.
Mongo Disk Usage

MongoDB allocates disk space per collection, so as a collection grows, it will gradually use more of the underlying disk space, allocating it to a specific collection. Freeing space in a collection by deleting records will not release it back to the operating system, it is still claimed by MongoDB. It will also be reserved to the same collection and will be reused, so new file records will reuse the Free space in the Files Collection.
However, as we insert new documents into the other collections, they cannot use the space freed in the files collection, so will gradually also claim more of the underlying disk so they can grow. This means that even though we are currently deleting more file records than we insert, our disk usage is still growing, although significantly slower.
In order to fully reclaim the free space within a collection in a MongoDB cluster, you need to wipe a node and perform a full re-sync – the last time we did this it took a full week to re-sync one node, so it is not something we want to do often – there are 3 nodes!
As a result, we want to get down to 60% usage before performing a full re-sync across all 3 nodes, one at a time.
