As mentioned in Original Architecture our application stored both Build Metadata and File contents in MongoDB.
MongoDB can store files using GridFS which:
- Allow the storing of files that exceed the BSON doc limit of 16 MB
- Files are stored in binary chunks around 256k in size
- Drivers or command line tool
- Transparent chunking to application
This was great for a proof-of-concept but as more teams started to onboard to our application the MongoDB started to get very full!
At $COMPANY, MongoDB is available in T-Shirt sizes so the first thing to buy some time was to upgrade to XL!
MongoDB made this easy, we could add the new XL nodes into our Replica Set one at a time and give them time to do sync the data. Once they were ready we could remove the smaller nodes from the Replica Set.
The Mongo team politely advised us that they had no plans for an XXL Mongo DB, and perhaps we needed to look at Horizontal Scaling of our Mongo DB. Our Mongo DB is configured as a 3 node cluster with Replication between the nodes, each node in a different data center, which is great for CoB!! To scale our Mongo DB instance would mean using Sharding, which would mean a lot more hardware.
The cost per gigabyte of storage was too expensive, so we had to look for alternatives.
MongoDB OpLog
The next issue we encountered was that we were generating alerts as our OpLog was less than 24 hours!
When a new node is added to a Mongo Replication Set, it will first do a full sync of the DB which is time consuming.
In a replica set, all write transactions will happen on the master node, as it executes a transaction it will store the transaction in a fixed size collection called the OpLog (Operation Log)
This means that secondary nodes just need to sync the OpLog from master and reply the transactions to reach the same state as master.
This OpLog is a capped size mongo collection, so when it has reached its max size (default max of 50GB) then new transactions added will push the oldest transactions out of the OpLog.
I have tried to show this in the animation below.
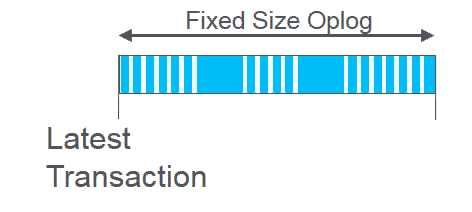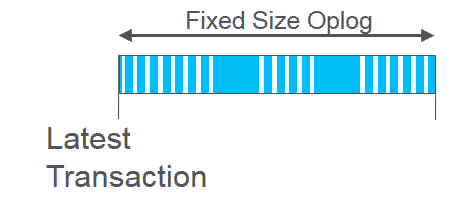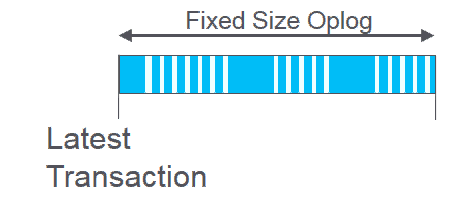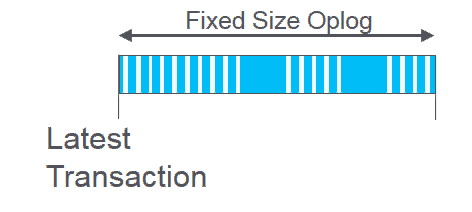
An important metric in an OpLog is the age of the oldest entry in the OpLog.
Assuming all nodes are in sync and a node goes down, if your OpLog stores 7 days of transactions then you have approx 7 days to get the node back online and it can use the OpLog to resync.
This avoids Mongo having to do a full resync. If your OpLog is less than 24 hours then you make the Mongo DB team nervous!
As mentioned, we stored binary files in Mongo. Inserting a binary file to mongo also needs to be recorded in the OpLog, along with the file contents, as depicted by the larger blocks in the animation.
Inserting 1GB files soon brings down your OpLog times!
File De-Duplication
Our Services already had server side de-duplication, when a file was uploaded it was fingerprinted, if we already stored a file with a matching fingerprint then we deleted the new file. However, Mongo still stored the Insert transaction for the file in the OpLog, it just also contains a delete for the file immediately after!
We updated our client code to calculate the fingerprint on client side and send the fingerprint to our Services which would determine if it was a duplicate or original. The Client would then only upload files which were not duplicates.
This reduced the number of file uploads by 99.5%
Which corresponded to a 70% reduction in data uploaded.
